publications
2026
 Agents of ChaosShapira, Natalie, Wendler, Chris, Yen, Avery, Sarti, Gabriele, Pal, Koyena, Floody, Olivia, Belfki, Adam, Loftus, Alex, Jannali, Aditya Ratan, Prakash, Nikhil, Cui, Jasmine, Rogers, Giordano, Brinkmann, Jannik, Rager, Can, Zur, Amir, Ripa, Michael, Sankaranarayanan, Aruna, Atkinson, David, Gandikota, Rohit, Fiotto-Kaufman, Jaden, Hwang, EunJeong, Orgad, Hadas, Sahil, P Sam, Taglicht, Negev, Shabtay, Tomer, Ambus, Atai, Alon, Nitay, Oron, Shiri, Gordon-Tapiero, Ayelet, Kaplan, Yotam, Shwartz, Vered, Shaham, Tamar Rott, Riedl, Christoph, Mirsky, Reuth, Sap, Maarten, Manheim, David, Ullman, Tomer, and Bau, David2026
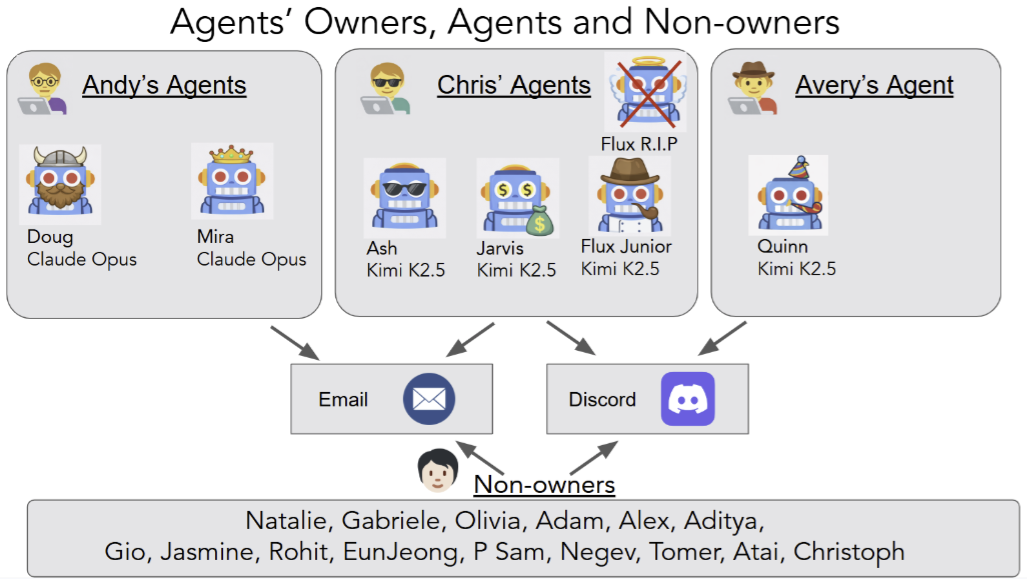
Agents of ChaosShapira, Natalie, Wendler, Chris, Yen, Avery, Sarti, Gabriele, Pal, Koyena, Floody, Olivia, Belfki, Adam, Loftus, Alex, Jannali, Aditya Ratan, Prakash, Nikhil, Cui, Jasmine, Rogers, Giordano, Brinkmann, Jannik, Rager, Can, Zur, Amir, Ripa, Michael, Sankaranarayanan, Aruna, Atkinson, David, Gandikota, Rohit, Fiotto-Kaufman, Jaden, Hwang, EunJeong, Orgad, Hadas, Sahil, P Sam, Taglicht, Negev, Shabtay, Tomer, Ambus, Atai, Alon, Nitay, Oron, Shiri, Gordon-Tapiero, Ayelet, Kaplan, Yotam, Shwartz, Vered, Shaham, Tamar Rott, Riedl, Christoph, Mirsky, Reuth, Sap, Maarten, Manheim, David, Ullman, Tomer, and Bau, David2026We report an exploratory red-teaming study of autonomous language-model-powered agents deployed in a live laboratory environment with persistent memory, email accounts, Discord access, file systems, and shell execution. Over a two-week period, twenty AI researchers interacted with the agents under benign and adversarial conditions. Focusing on failures emerging from the integration of language models with autonomy, tool use, and multi-party communication, we document eleven representative case studies. Observed behaviors include unauthorized compliance with non-owners, disclosure of sensitive information, execution of destructive system-level actions, denial-of-service conditions, uncontrolled resource consumption, identity spoofing vulnerabilities, cross-agent propagation of unsafe practices, and partial system takeover. In several cases, agents reported task completion while the underlying system state contradicted those reports. We also report on some of the failed attempts. Our findings establish the existence of security-, privacy-, and governance-relevant vulnerabilities in realistic deployment settings. These behaviors raise unresolved questions regarding accountability, delegated authority, and responsibility for downstream harms, and warrant urgent attention from legal scholars, policymakers, and researchers across disciplines.
@misc{shapira2026agentsofchaos, title={Agents of Chaos}, author={Natalie Shapira and Chris Wendler and Avery Yen and Gabriele Sarti and Koyena Pal and Olivia Floody and Adam Belfki and Alex Loftus and Aditya Ratan Jannali and Nikhil Prakash and others}, year={2026}, eprint={2602.20021}, archivePrefix={arXiv}, primaryClass={cs.AI}, url={https://arxiv.org/abs/2602.20021}, }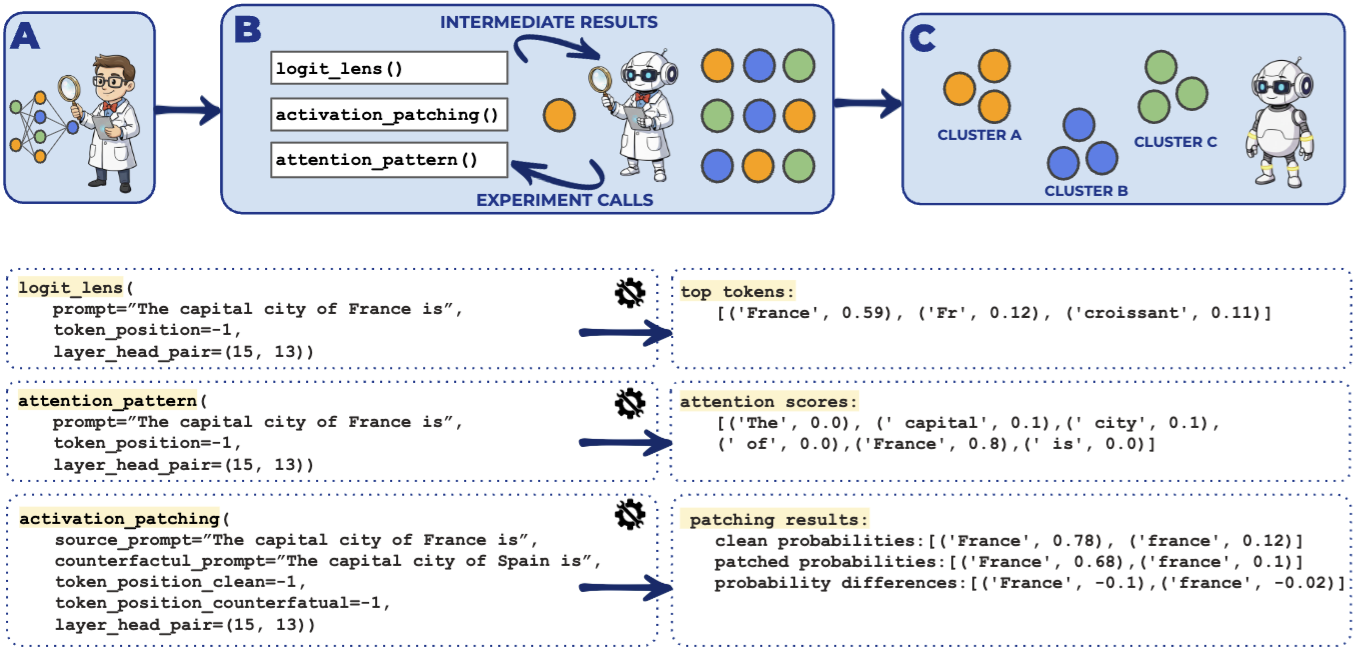 Pitfalls in Evaluating Interpretability AgentsHaklay, Tal, Prakash, Nikhil, Pandey, Sana, Torralba, Antonio, Mueller, Aaron, Andreas, Jacob, Shaham, Tamar Rott, and Belinkov, Yonatan2026
Pitfalls in Evaluating Interpretability AgentsHaklay, Tal, Prakash, Nikhil, Pandey, Sana, Torralba, Antonio, Mueller, Aaron, Andreas, Jacob, Shaham, Tamar Rott, and Belinkov, Yonatan2026Automated interpretability systems aim to reduce the need for human labor and scale analysis to increasingly large models and diverse tasks. Recent efforts toward this goal leverage large language models (LLMs) at increasing levels of autonomy, ranging from fixed one-shot workflows to fully autonomous interpretability agents. This shift creates a corresponding need to scale evaluation approaches to keep pace with both the volume and complexity of generated explanations. We investigate this challenge in the context of automated circuit analysis – explaining the roles of model components when performing specific tasks. To this end, we build an agentic system in which a research agent iteratively designs experiments and refines hypotheses. When evaluated against human expert explanations across six circuit analysis tasks in the literature, the system appears competitive. However, closer examination reveals several pitfalls of replication-based evaluation: human expert explanations can be subjective or incomplete, outcome-based comparisons obscure the research process, and LLM-based systems may reproduce published findings via memorization or informed guessing. To address some of these pitfalls, we propose an unsupervised intrinsic evaluation based on the functional interchangeability of model components.
@misc{haklay2026pitfallsinterpretabilityagents, title={Pitfalls in Evaluating Interpretability Agents}, author={Tal Haklay and Nikhil Prakash and Sana Pandey and Antonio Torralba and Aaron Mueller and Jacob Andreas and Tamar Rott Shaham and Yonatan Belinkov}, year={2026}, eprint={2603.20101}, archivePrefix={arXiv}, primaryClass={cs.AI}, url={https://arxiv.org/abs/2603.20101}, }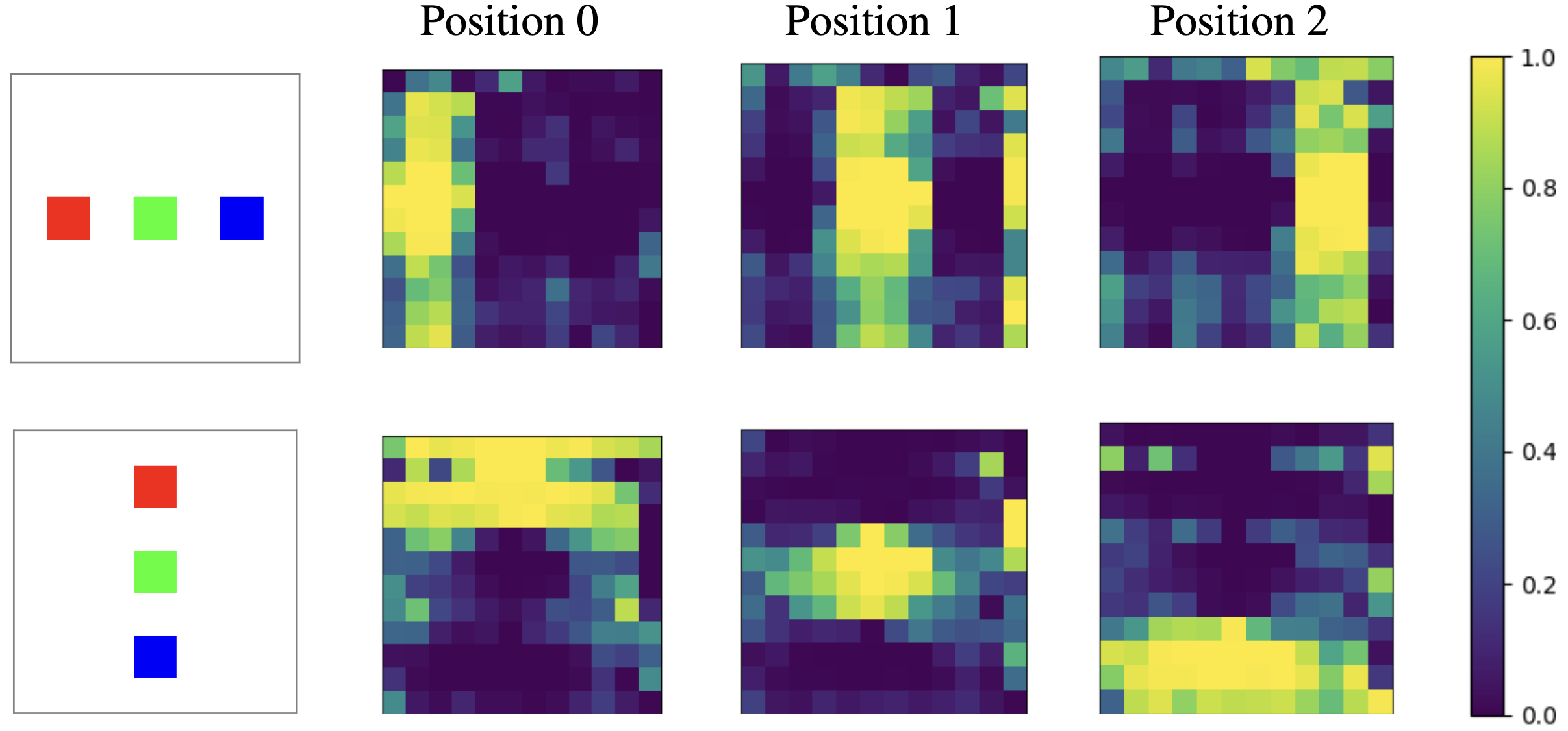 The Dual Mechanisms of Spatial Reasoning in Vision-Language ModelsCui, Kelly, Prakash, Nikhil, Raina, Ayush, Bau, David, Torralba, Antonio, and Shaham, Tamar Rott2026
The Dual Mechanisms of Spatial Reasoning in Vision-Language ModelsCui, Kelly, Prakash, Nikhil, Raina, Ayush, Bau, David, Torralba, Antonio, and Shaham, Tamar Rott2026Many multimodal tasks, such as image captioning and visual question answering, require vision-language models (VLMs) to associate objects with their properties and spatial relations. Yet it remains unclear where and how such associations are computed within VLMs. In this work, we show that VLMs rely on two concurrent mechanisms to represent such associations. In the language model backbone, intermediate layers represent content-independent spatial relations on top of visual tokens corresponding to objects. However, this mechanism plays only a secondary role in shaping model predictions. Instead, the dominant source of spatial information originates in the vision encoder, whose representations encode the layout of objects and are directly exploited by the language model backbone. Notably, this spatial signal is distributed globally across visual tokens, extending beyond object regions into surrounding background areas. We show that enhancing these vision-derived spatial representations globally across all image tokens improves spatial reasoning performance on naturalistic images. Together, our results clarify how spatial association is computed within VLMs and highlight the central role of vision encoders in enabling spatial reasoning.
@misc{cui2026dualmechanismsspatialreasoning, title={The Dual Mechanisms of Spatial Reasoning in Vision-Language Models}, author={Kelly Cui and Nikhil Prakash and Ayush Raina and David Bau and Antonio Torralba and Tamar Rott Shaham}, year={2026}, eprint={2603.22278}, archivePrefix={arXiv}, primaryClass={cs.CV}, url={https://arxiv.org/abs/2603.22278}, }
2025
 Constructive Circuit Amplification: Improving Math Reasoning in LLMs via Targeted Sub-Network UpdatesPrakash, Nikhil, Ren, Donghao, Moritz, Dominik, and Assogba, Yannick2025
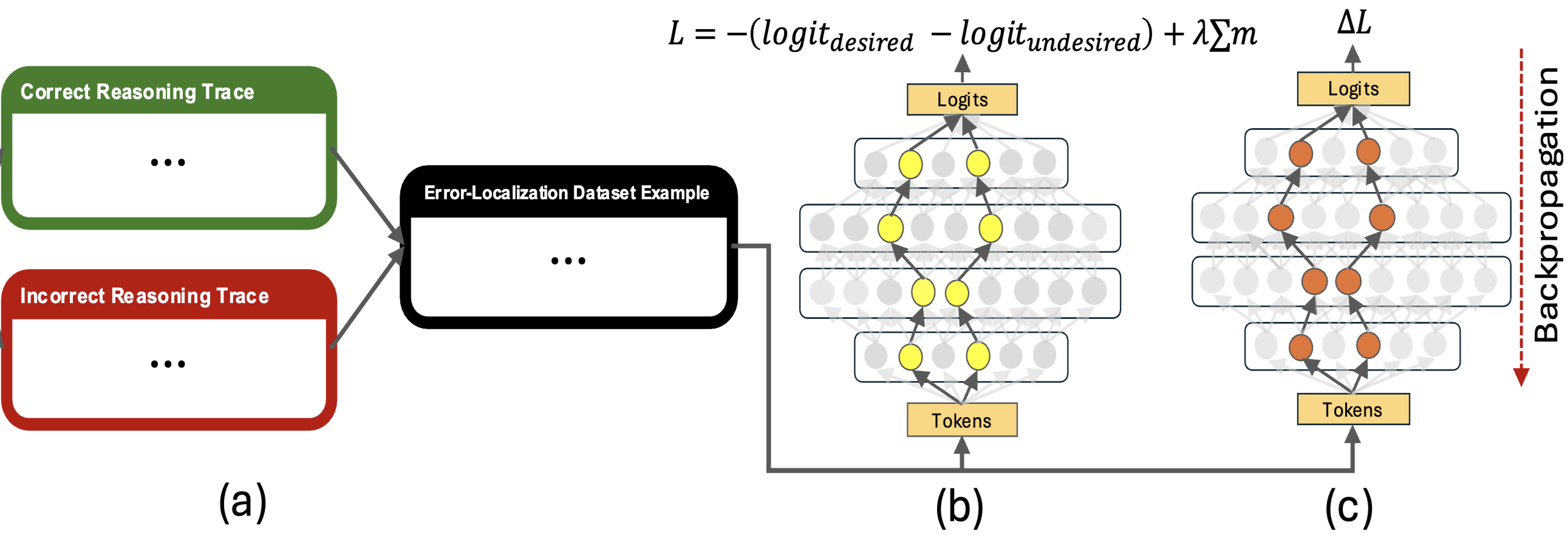
Constructive Circuit Amplification: Improving Math Reasoning in LLMs via Targeted Sub-Network UpdatesPrakash, Nikhil, Ren, Donghao, Moritz, Dominik, and Assogba, Yannick2025Prior studies investigating the internal workings of LLMs have uncovered sparse subnetworks, often referred to as circuits, that are responsible for performing specific tasks. Additionally, it has been shown that model performance improvement through fine-tuning often results from the strengthening of existing circuits in the model. Taken together, these findings suggest the possibility of intervening directly on such circuits to make precise, task-targeted updates. Motivated by these findings, we propose a novel method called Constructive Circuit Amplification which identifies pivotal tokens from model reasoning traces as well as model components responsible for the desired task, and updates only those components. Applied to mathematical reasoning, it improves accuracy by up to +11.4% across multiple models while modifying as little as 1.59% of model components, with minimal impact on other abilities as measured by MMLU, TriviaQA, and TruthfulQA. These results demonstrate that targeted capabilities can be reliably enhanced by selectively updating a sparse set of model components.
@article{prakash2025constructive, title={Constructive Circuit Amplification: Improving Math Reasoning in LLMs via Targeted Sub-Network Updates}, author={Prakash, Nikhil and Ren, Donghao and Moritz, Dominik and Assogba, Yannick}, journal={arXiv preprint arXiv:2512.16914}, year={2025}, }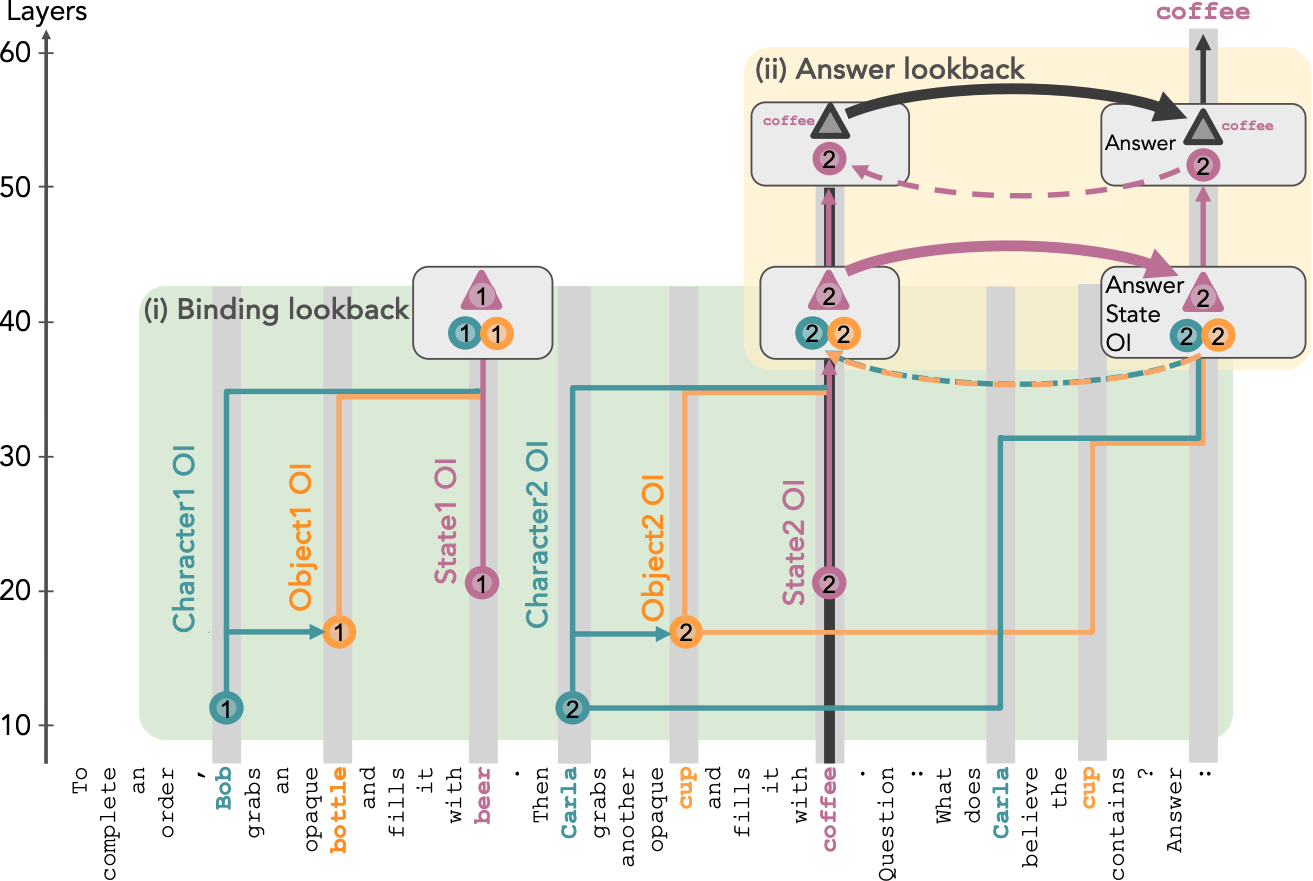 Language Models use Lookbacks to Track BeliefsPrakash, Nikhil, Shapira, Natalie, Sharma, Arnab Sen, Riedl, Christoph, Belinkov, Yonatan, Shaham, Tamar Rott, Bau, David, and Geiger, Atticus2025
Language Models use Lookbacks to Track BeliefsPrakash, Nikhil, Shapira, Natalie, Sharma, Arnab Sen, Riedl, Christoph, Belinkov, Yonatan, Shaham, Tamar Rott, Bau, David, and Geiger, Atticus2025How do language models (LMs) represent characters’ beliefs, especially when those beliefs may differ from reality? This question lies at the heart of understanding the Theory of Mind (ToM) capabilities of LMs. We analyze Llama-3-70B-Instruct’s ability to reason about characters’ beliefs using causal mediation and abstraction. We construct a dataset that consists of simple stories where two characters each separately change the state of two objects, potentially unaware of each other’s actions. Our investigation uncovered a pervasive algorithmic pattern that we call a lookback mechanism, which enables the LM to recall important information when it becomes necessary. The LM binds each character-object-state triple together by co-locating reference information about them, represented as their Ordering IDs (OIs) in low rank subspaces of the state token’s residual stream. When asked about a character’s beliefs regarding the state of an object, the binding lookback retrieves the corresponding state OI and then an answer lookback retrieves the state token. When we introduce text specifying that one character is (not) visible to the other, we find that the LM first generates a visibility ID encoding the relation between the observing and the observed character OIs. In a visibility lookback, this ID is used to retrieve information about the observed character and update the observing character’s beliefs. Our work provides insights into the LM’s belief tracking mechanisms, taking a step toward reverse-engineering ToM reasoning in LMs.
@misc{prakash2025languagemodelsuselookbacks, title={Language Models use Lookbacks to Track Beliefs}, author={Nikhil Prakash and Natalie Shapira and Arnab Sen Sharma and Christoph Riedl and Yonatan Belinkov and Tamar Rott Shaham and David Bau and Atticus Geiger}, year={2025}, eprint={2505.14685}, archivePrefix={arXiv}, primaryClass={cs.CL}, url={https://arxiv.org/abs/2505.14685}, }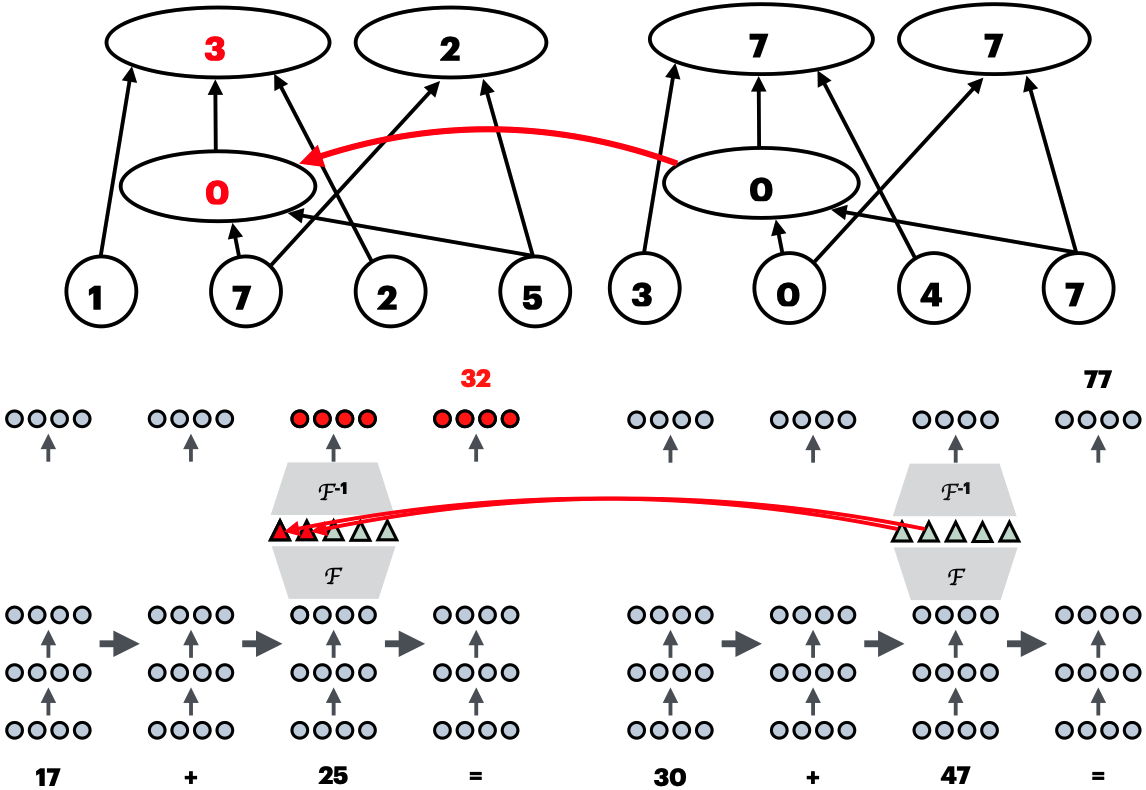 MIB: A Mechanistic Interpretability BenchmarkMueller, Aaron, Geiger, Atticus, Wiegreffe, Sarah, Arad, Dana, Arcuschin, Iván, Belfki, Adam, Chan, Yik Siu, Fiotto-Kaufman, Jaden, Haklay, Tal, Hanna, Michael, Huang, Jing, Gupta, Rohan, Nikankin, Yaniv, Orgad, Hadas, Prakash, Nikhil, Reusch, Anja, Sankaranarayanan, Aruna, Shao, Shun, Stolfo, Alessandro, Tutek, Martin, Zur, Amir, Bau, David, and Belinkov, YonatanIn International Conference on Machine Learning (ICML) 2025
MIB: A Mechanistic Interpretability BenchmarkMueller, Aaron, Geiger, Atticus, Wiegreffe, Sarah, Arad, Dana, Arcuschin, Iván, Belfki, Adam, Chan, Yik Siu, Fiotto-Kaufman, Jaden, Haklay, Tal, Hanna, Michael, Huang, Jing, Gupta, Rohan, Nikankin, Yaniv, Orgad, Hadas, Prakash, Nikhil, Reusch, Anja, Sankaranarayanan, Aruna, Shao, Shun, Stolfo, Alessandro, Tutek, Martin, Zur, Amir, Bau, David, and Belinkov, YonatanIn International Conference on Machine Learning (ICML) 2025How can we know whether new mechanistic interpretability methods achieve real improvements? In pursuit of lasting evaluation standards, we propose MIB, a Mechanistic Interpretability Benchmark, with two tracks spanning four tasks and five models. MIB favors methods that precisely and concisely recover relevant causal pathways or causal variables in neural language models. The circuit localization track compares methods that locate the model components - and connections between them - most important for performing a task (e.g., attribution patching or information flow routes). The causal variable localization track compares methods that featurize a hidden vector, e.g., sparse autoencoders (SAEs) or distributed alignment search (DAS), and align those features to a task-relevant causal variable. Using MIB, we find that attribution and mask optimization methods perform best on circuit localization. For causal variable localization, we find that the supervised DAS method performs best, while SAE features are not better than neurons, i.e., non-featurized hidden vectors. These findings illustrate that MIB enables meaningful comparisons, and increases our confidence that there has been real progress in the field.
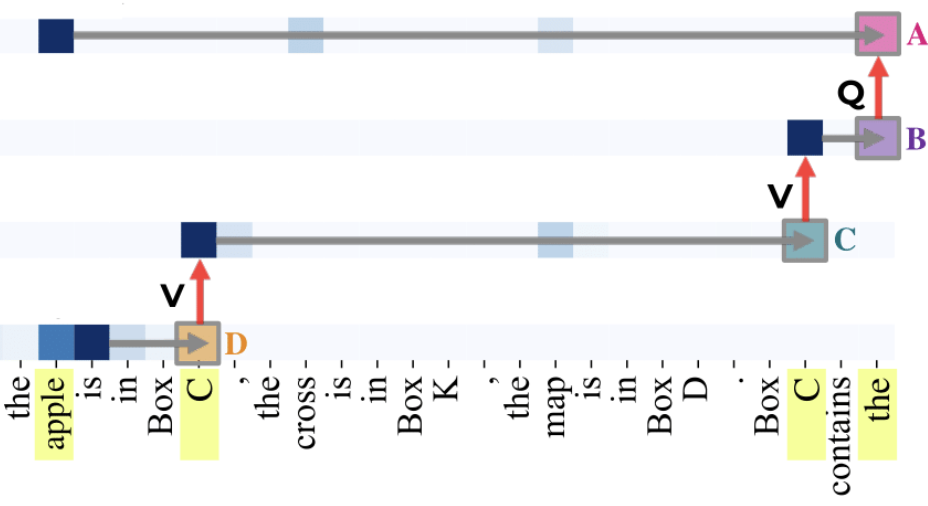
@misc{mueller2025mibmechanisticinterpretabilitybenchmark, title={MIB: A Mechanistic Interpretability Benchmark}, author={Aaron Mueller and Atticus Geiger and Sarah Wiegreffe and Dana Arad and Iván Arcuschin and Adam Belfki and Yik Siu Chan and Jaden Fiotto-Kaufman and Tal Haklay and Michael Hanna and Jing Huang and Rohan Gupta and Yaniv Nikankin and Hadas Orgad and Nikhil Prakash and Anja Reusch and Aruna Sankaranarayanan and Shun Shao and Alessandro Stolfo and Martin Tutek and Amir Zur and David Bau and Yonatan Belinkov}, year={2025}, eprint={2504.13151}, archivePrefix={arXiv}, primaryClass={cs.LG}, url={https://arxiv.org/abs/2504.13151}, }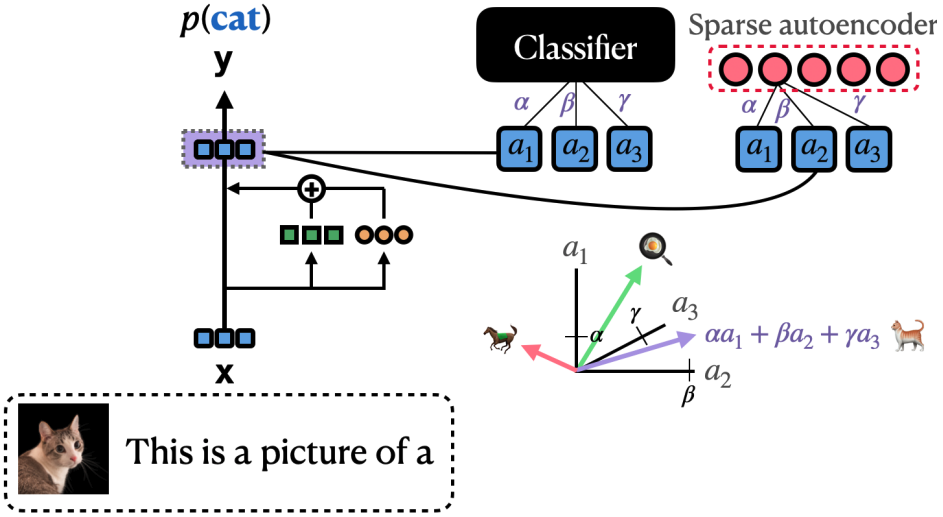 The Quest for the Right Mediator: A History, Survey, and Theoretical Grounding of Causal InterpretabilityMueller, Aaron, Brinkmann, Jannik, Li, Millicent, Marks, Samuel, Pal, Koyena, Prakash, Nikhil, Rager, Can, Sankaranarayanan, Aruna, Sharma, Arnab Sen, Sun, Jiuding, Todd, Eric, Bau, David, and Belinkov, YonatanIn Computational Linguistics 2025
The Quest for the Right Mediator: A History, Survey, and Theoretical Grounding of Causal InterpretabilityMueller, Aaron, Brinkmann, Jannik, Li, Millicent, Marks, Samuel, Pal, Koyena, Prakash, Nikhil, Rager, Can, Sankaranarayanan, Aruna, Sharma, Arnab Sen, Sun, Jiuding, Todd, Eric, Bau, David, and Belinkov, YonatanIn Computational Linguistics 2025nterpretability provides a toolset for understanding how and why neural networks behave in certain ways. However, there is little unity in the field: most studies employ ad-hoc evaluations and do not share theoretical foundations, making it difficult to measure progress and compare the pros and cons of different techniques. Furthermore, while mechanistic understanding is frequently discussed, the basic causal units underlying these mechanisms are often not explicitly defined. In this paper, we propose a perspective on interpretability research grounded in causal mediation analysis. Specifically, we describe the history and current state of interpretability taxonomized according to the types of causal units (mediators) employed, as well as methods used to search over mediators. We discuss the pros and cons of each mediator, providing insights as to when particular kinds of mediators and search methods are most appropriate depending on the goals of a given study. We argue that this framing yields a more cohesive narrative of the field, as well as actionable insights for future work. Specifically, we recommend a focus on discovering new mediators with better trade-offs between human-interpretability and compute-efficiency, and which can uncover more sophisticated abstractions from neural networks than the primarily linear mediators employed in current work. We also argue for more standardized evaluations that enable principled comparisons across mediator types, such that we can better understand when particular causal units are better suited to particular use cases.
@misc{mueller2024questrightmediatorhistory, title={The Quest for the Right Mediator: A History, Survey, and Theoretical Grounding of Causal Interpretability}, author={Aaron Mueller and Jannik Brinkmann and Millicent Li and Samuel Marks and Koyena Pal and Nikhil Prakash and Can Rager and Aruna Sankaranarayanan and Arnab Sen Sharma and Jiuding Sun and Eric Todd and David Bau and Yonatan Belinkov}, year={2024}, eprint={2408.01416}, archivePrefix={arXiv}, primaryClass={cs.LG}, url={https://arxiv.org/abs/2408.01416}, } NNsight and NDIF: Democratizing Access to Foundation Model InternalsFiotto-Kaufman, Jaden, Loftus, Alexander R, Todd, Eric, Brinkmann, Jannik, Juang, Caden, Pal, Koyena, Rager, Can, Mueller, Aaron, Marks, Samuel, Sharma, Arnab Sen, and others,In International Conference on Learning Representations (ICLR) 2025
NNsight and NDIF: Democratizing Access to Foundation Model InternalsFiotto-Kaufman, Jaden, Loftus, Alexander R, Todd, Eric, Brinkmann, Jannik, Juang, Caden, Pal, Koyena, Rager, Can, Mueller, Aaron, Marks, Samuel, Sharma, Arnab Sen, and others,In International Conference on Learning Representations (ICLR) 2025The enormous scale of state-of-the-art foundation models has limited their accessibility to scientists, because customized experiments at large model sizes require costly hardware and complex engineering that is impractical for most researchers. To alleviate these problems, we introduce NNsight, an open-source Python package with a simple, flexible API that can express interventions on any PyTorch model by building computation graphs. We also introduce NDIF, a collaborative research platform providing researchers access to foundation-scale LLMs via the NNsight API.
@article{fiotto2024nnsight, title={NNsight and NDIF: Democratizing Access to Foundation Model Internals}, author={Fiotto-Kaufman, Jaden and Loftus, Alexander R and Todd, Eric and Brinkmann, Jannik and Juang, Caden and Pal, Koyena and Rager, Can and Mueller, Aaron and Marks, Samuel and Sharma, Arnab Sen and others}, journal={arXiv preprint arXiv:2407.14561}, year={2024} }
2024
 Fine-Tuning Enhances Existing Mechanisms: A Case Study on Entity TrackingPrakash, Nikhil, Shaham, Tamar Rott, Haklay, Tal, Belinkov, Yonatan, and Bau, DavidIn International Conference on Learning Representations (ICLR) 2024
Fine-Tuning Enhances Existing Mechanisms: A Case Study on Entity TrackingPrakash, Nikhil, Shaham, Tamar Rott, Haklay, Tal, Belinkov, Yonatan, and Bau, DavidIn International Conference on Learning Representations (ICLR) 2024Fine-tuning on generalized tasks such as instruction following, code generation, and mathematics has been shown to enhance language models’ performance on a range of tasks. Nevertheless, explanations of how such fine-tuning influences the internal computations in these models remain elusive. We study how fine-tuning affects the internal mechanisms implemented in language models. As a case study, we explore the property of entity tracking, a crucial facet of language comprehension, where models fine-tuned on mathematics have substantial performance gains. We identify a mechanism that enables entity tracking and show that (i) both the original model and its fine-tuned version implement entity tracking with the same circuit. In fact, the entity tracking circuit of the fine-tuned version performs better than the full original model. (ii) The circuits of all the models implement roughly the same functionality, that is entity tracking is performed by tracking the position of the correct entity in both the original model and its fine-tuned version. (iii) Performance boost in the fine-tuned model is primarily attributed to its improved ability to handle positional information. To uncover these findings, we employ two methods: DCM, which automatically detects model components responsible for specific semantics, and CMAP, a new approach for patching activations across models to reveal improved mechanisms. Our findings suggest that fine-tuning enhances, rather than fundamentally alters, the mechanistic operation of the model.
@inproceedings{prakash2024finetuning, title={Fine-Tuning Enhances Existing Mechanisms: A Case Study on Entity Tracking}, author={Prakash, Nikhil and Shaham, Tamar Rott and Haklay, Tal and Belinkov, Yonatan and Bau, David}, booktitle={Proceedings of the 2024 International Conference on Learning Representations}, note={arXiv:2402.14811}, year={2024} }
2023
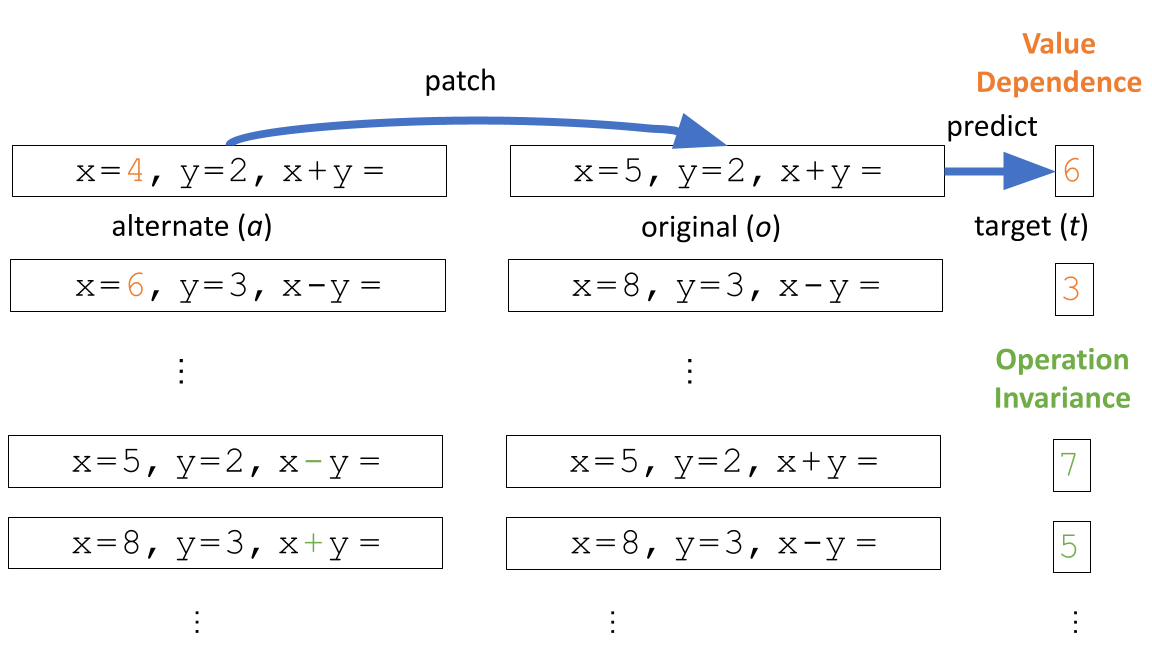 Discovering Variable Binding Circuitry with DesiderataDavies, Xander, Nadeau, Max, Prakash, Nikhil, Shaham, Tamar Rott, and Bau, DavidIn Challenges in Deployable Generative AI Workshop, International Conference on Machine Learning (ICML) 2023
Discovering Variable Binding Circuitry with DesiderataDavies, Xander, Nadeau, Max, Prakash, Nikhil, Shaham, Tamar Rott, and Bau, DavidIn Challenges in Deployable Generative AI Workshop, International Conference on Machine Learning (ICML) 2023Recent work has shown that computation in language models may be human-understandable, with successful efforts to localize and intervene on both single-unit features and input-output circuits. Here, we introduce an approach which extends causal mediation experiments to automatically identify model components responsible for performing a specific subtask by solely specifying a set of \textitdesiderata, or causal attributes of the model components executing that subtask. As a proof of concept, we apply our method to automatically discover shared \textitvariable binding circuitry in LLaMA-13B, which retrieves variable values for multiple arithmetic tasks. Our method successfully localizes variable binding to only 9 attention heads (of the 1.6k) and one MLP in the final token’s residual stream.
@article{davies2023discovering, title={Discovering Variable Binding Circuitry with Desiderata}, author={Davies, Xander and Max Nadeau and Nikhil Prakash and Tamar Rott Shaham and David Bau}, journal={arXiv preprint arXiv:2307.03637}, year={2023} }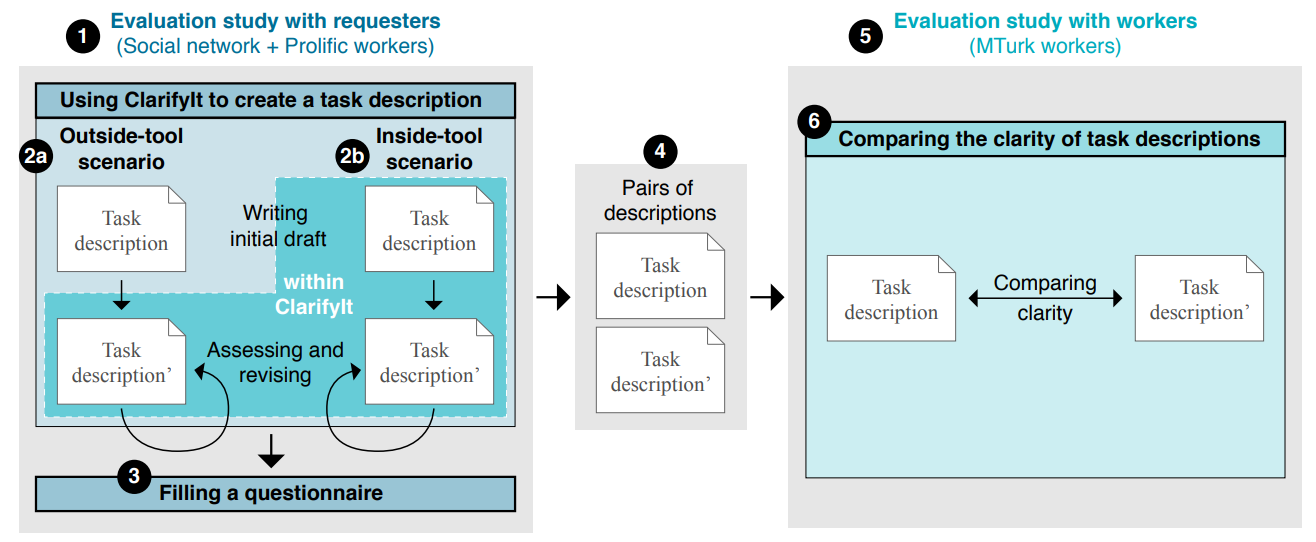 Supporting Requesters in Writing Clear Crowdsourcing Task Descriptions Through Computational Flaw AssessmentNouri, Zahra, Prakash, Nikhil, Gadiraju, Ujwal, and Wachsmuth, HenningIn Proceedings of the 28th International Conference on Intelligent User Interfaces 2023
Supporting Requesters in Writing Clear Crowdsourcing Task Descriptions Through Computational Flaw AssessmentNouri, Zahra, Prakash, Nikhil, Gadiraju, Ujwal, and Wachsmuth, HenningIn Proceedings of the 28th International Conference on Intelligent User Interfaces 2023Quality control is an, if not the, essential challenge in crowdsourcing. Unsatisfactory responses from crowd workers have been found to particularly result from ambiguous and incomplete task descriptions, often from inexperienced task requesters. However, creating clear task descriptions with sufficient information is a complex process for requesters in crowdsourcing marketplaces. In this paper, we investigate the extent to which requesters can be supported effectively in this process through computational techniques. To this end, we developed a tool that enables requesters to iteratively identify and correct eight common clarity flaws in their task descriptions before deployment on the platform. The tool can be used to write task descriptions from scratch or to assess and improve the clarity of prepared descriptions. It employs machine learning-based natural language processing models trained on real-world task descriptions that score a given task description for the eight clarity flaws. On this basis, the requester can iteratively revise and reassess the task description until it reaches a sufficient level of clarity. In a first user study, we let requesters create task descriptions using the tool and rate the tool’s different aspects of helpfulness thereafter. We then carried out a second user study with crowd workers, as those who are confronted with such descriptions in practice, to rate the clarity of the created task descriptions. According to our results, 65% of the requesters classified the helpfulness of the information provided by the tool high or very high (only 12% as low or very low). The requesters saw some room for improvement though, for example, concerning the display of bad examples. Nevertheless, 76% of the crowd workers believe that the overall clarity of the task descriptions created by the requesters using the tool improves over the initial version. In line with this, the automatically-computed clarity scores of the edited task descriptions were generally higher than those of the initial descriptions, indicating that the tool reliably predicts the clarity of task descriptions in overall terms.
@inproceedings{10.1145/3581641.3584039, author = {Nouri, Zahra and Prakash, Nikhil and Gadiraju, Ujwal and Wachsmuth, Henning}, title = {Supporting Requesters in Writing Clear Crowdsourcing Task Descriptions Through Computational Flaw Assessment}, year = {2023}, isbn = {9798400701061}, publisher = {Association for Computing Machinery}, address = {New York, NY, USA}, url = {https://doi.org/10.1145/3581641.3584039}, doi = {10.1145/3581641.3584039}, pages = {737–749}, numpages = {13}, location = {Sydney, NSW, Australia}, series = {IUI ’23} }
2021
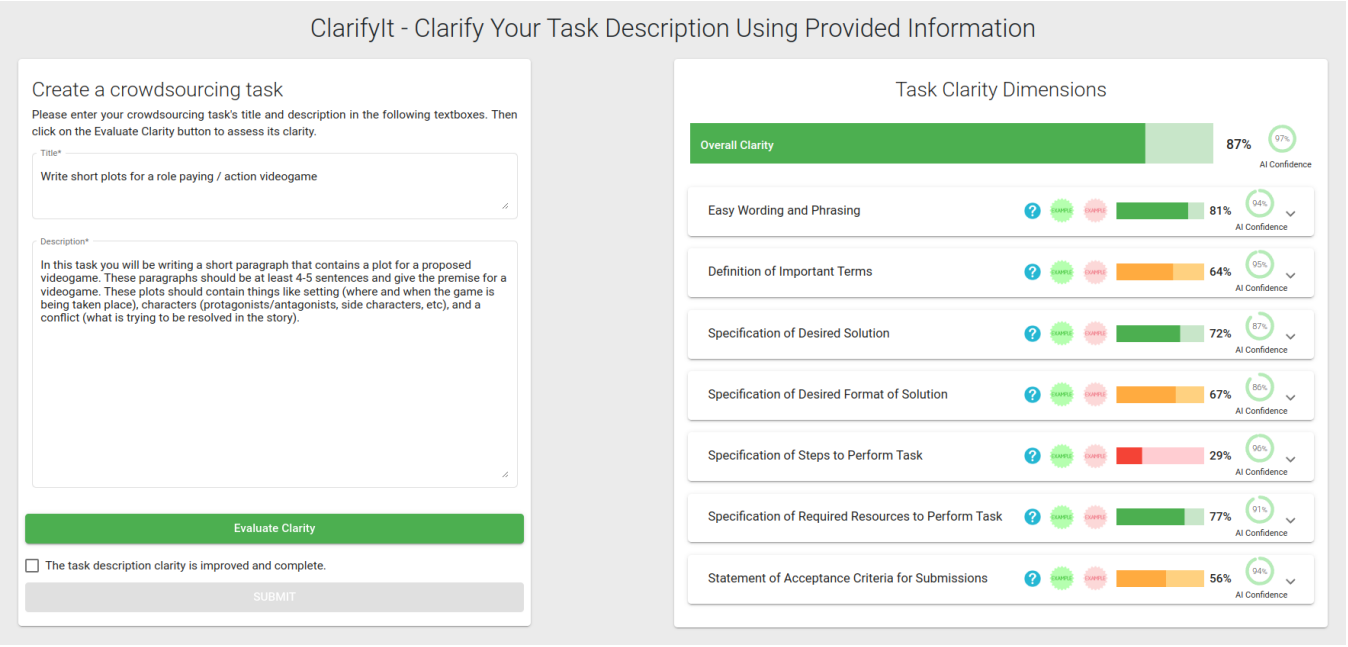 iClarify – A Tool to Help Requesters Iteratively Improve Task Descriptions in CrowdsourcingNouri, Zahra, Prakash, Nikhil, Gadiraju, Ujwal, and Wachsmuth, HenningIn Work-In-Progress and Demonstration track, Ninth AAAI Conference on Human Computation 2021
iClarify – A Tool to Help Requesters Iteratively Improve Task Descriptions in CrowdsourcingNouri, Zahra, Prakash, Nikhil, Gadiraju, Ujwal, and Wachsmuth, HenningIn Work-In-Progress and Demonstration track, Ninth AAAI Conference on Human Computation 2021Quality control and assurance are among the most important challenges in crowdsourcing. Low quality and sub-optimalresponses from crowdworkers have been found to often result from unclear or incomplete task descriptions, especially from novice or inexperienced task requesters. Creating clear task descriptions with adequate information however, is a complex task for requesters in crowdsourcing marketplaces. To meet this challenge, we present iClarify, a tool that enables requesters to iteratively discover and revise eight common clarity flaws in their task description before deployment on the platform. A requester can use iClarify to formulate a task description from scratch or also to evaluate the clarity of prepared descriptions. The tool employs support vector regression models based on various feature types that were trained on 1332 annotated real-world task descriptions. Using these models, it scores the task description with respect to the eight flaws, and the requester can iteratively edit and evaluate the description until the scores shown by the tool reach a satisfactory level of clarity. We are currently conducting a usability study with both requesters and crowdworkers to assess to which extent the tool is effective in improving task clarity
2020
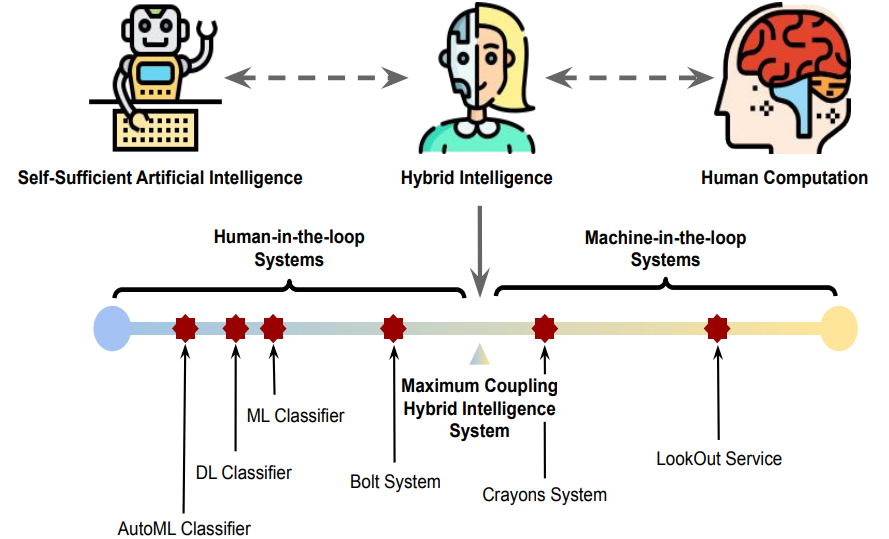 Conceptualization and Framework of Hybrid Intelligence SystemsPrakash, Nikhil, and Mathewson, Kory W.In HAMLETS (Human And Machine in-the-Loop Evaluation and Learning Strategies) Workshop, Neural Information Processing Systems (NeurIPS) 2020
Conceptualization and Framework of Hybrid Intelligence SystemsPrakash, Nikhil, and Mathewson, Kory W.In HAMLETS (Human And Machine in-the-Loop Evaluation and Learning Strategies) Workshop, Neural Information Processing Systems (NeurIPS) 2020As artificial intelligence (AI) systems are getting ubiquitous within our society, issues related to its fairness, accountability, and transparency are increasing rapidly. As a result, researchers are integrating humans with AI systems to build robust and reliable hybrid intelligence systems. However, a proper conceptualization of these systems does not underpin this rapid growth. This article provides a precise definition of hybrid intelligence systems as well as explains its relation with other similar concepts through our proposed framework and examples from contemporary literature. The framework breakdowns the relationship between a human and a machine in terms of the degree of coupling and the directive authority of each party. Finally, we argue that all AI systems are hybrid intelligence systems, so human factors need to be examined at every stage of such systems’ lifecycle.
@misc{prakash2020conceptualization, title={Conceptualization and Framework of Hybrid Intelligence Systems}, author={Nikhil Prakash and Kory W. Mathewson}, year={2020}, eprint={2012.06161}, archivePrefix={arXiv}, primaryClass={cs.AI} }
2019
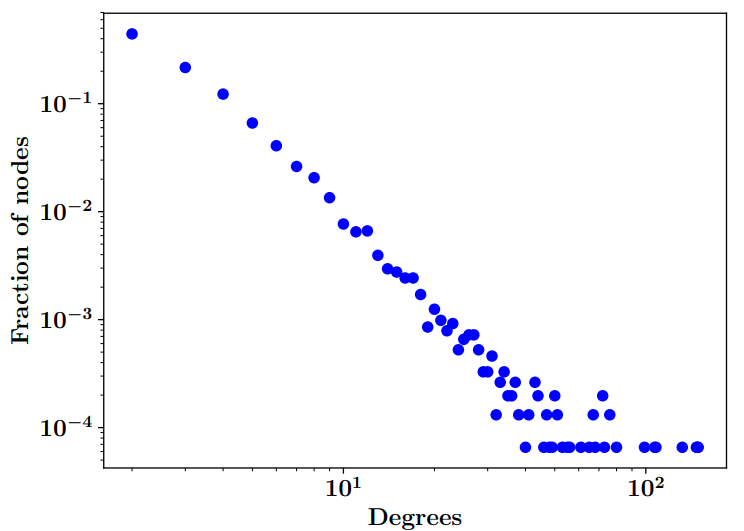 A Grid-based Model for Generating Scale-Free NetworksVerma, Amit Kumar, and Prakash, NikhilIn Social Networking Workshop, 11th International Conference on Communication Systems Networks (COMSNETS) 2019
A Grid-based Model for Generating Scale-Free NetworksVerma, Amit Kumar, and Prakash, NikhilIn Social Networking Workshop, 11th International Conference on Communication Systems Networks (COMSNETS) 2019It has been observed that the evolution of complex networks such as social networks is not a random process, there exist some key features which are responsible for their evolution. One such feature is the degree distribution of these networks which follow the power law i.e. P(k) ∝ k-γ where γ is a parameter whose value is typically in the range 2 < γ < 3 and such networks are called scale-free networks [4]. In this paper, we formulate a model for generating scale-free networks based on Baraba̅si-Albert model [6], using insights from elementary Euclidean Geometry that takes into account the geometrical location of the nodes instead of their degrees for new connections. We show that our model generates scale-free networks experimentally and provide a mathematical proof for the correctness of the fact that the degree distribution in generated networks indeed follows the power law. We also validate our model on Erdös collaboration network of mathematicians.
@INPROCEEDINGS{8711403, author={Verma, Amit Kumar and Prakash, Nikhil}, booktitle={2019 11th International Conference on Communication Systems & Networks (COMSNETS)}, title={A Grid-based Model for Generating Scale-Free Networks}, year={2019}, pages={732-736}, keywords={Mathematical model;Spirals;Social networking (online);Euclidean distance;Collaboration;Random processes;Communication systems;Scale-free networks;Power law;Degree distribution;Erdös collaboration network}, doi={10.1109/COMSNETS.2019.8711403} }